Cohen’s Kappa statistic
Cohen’s kappa statistic (κ) is a performance metric used to evaluate classification models, particularly in scenarios involving multiclass problems or imbalanced datasets. Its primary advantage over standard accuracy is that it accounts for the possibility of a classifier reaching a correct prediction purely by chance based on the frequency of each class.
1. Building Cohen’s Kappa
Cohen's kappa is derived from the values in a confusion matrix. It is built using two primary components: observed agreement (po) and expected agreement (pe).
- The Formula:
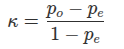
- Observed Agreement (po): This is the standard accuracy of the model, representing the proportion of instances that were correctly classified. From a 2x2 confusion matrix where a and d are true positives/negatives and b and c are errors:
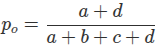
- Expected Agreement (pe): This represents the agreement that would occur if the classifier randomly guessed labels based on the actual and predicted frequencies of each class. It is the sum of the probabilities for each class being agreed upon by chance. For a two-class problem:
- pclass1: Multiply the proportion of actual class 1 instances by the proportion of predicted class 1 instances.
- pclass2: Multiply the proportion of actual class 2 instances by the proportion of predicted class 2 instances.
- Total pe: pclass1+pclass2.
2. How to Interpret Cohen’s Kappa
The value of Cohen’s kappa tells you how much better your model is performing compared to a random classifier.
- Value Range: The statistic is always less than or equal to 1.
- Thresholds for Success: While interpretation can vary, the following ranges are commonly used to assess model quality:
- 0.81 or higher: The model is considered "very good".
- 0.61 to 0.80: The model is considered "good".
- 0 or less: Indicates the model has a significant problem, potentially performing no better (or even worse) than random guessing.
3. Importance in Imbalanced Learning
Cohen’s kappa is highly valued in imbalanced learning because it prevents "fooling" the analyst with high accuracy scores on skewed data. In a dataset where one class dominates, a "dumb" model that always predicts the majority class would have high accuracy (po), but its expected agreement (pe) would also be very high. This would result in a low kappa score, correctly identifying the model as poor.
By subtracting pe from both the numerator and denominator, the metric effectively "normalizes" the performance, ensuring that a model must demonstrate genuine predictive power beyond what is expected by simple frequency-based guessing.