F1-Score
The F1-score (also known as the F-measure) is a single-number performance metric that provides a balanced summary of a classification model’s success by combining precision and recall. It is especially valuable for evaluating models on imbalanced datasets where accuracy can be highly misleading.
- Calculation and Formula
The F1-score is defined as the harmonic mean of precision and recall.
- Standard Formula: F1=2×Precision+RecallPrecision×Recall.
- Confusion Matrix Formula: Using counts of True Positives (TP), False Positives (FP), and False Negatives (FN), it is calculated as:
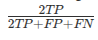
- Logic of the Harmonic Mean
Unlike a standard arithmetic average, the harmonic mean gives much more weight to low values.
- Requirement for Excellence: A classifier will only achieve a high F1-score if both precision and recall are high.
- Sensitivity to Extremes: If one metric is perfect (1.0) but the other is very low (e.g., 0.0001), the arithmetic mean would be roughly 0.5, while the F1-score would be near zero. This prevents "gaming" the metric by predicting only the most frequent class or identifying only one positive instance perfectly while missing all others.
- Why the F1-Score is Important
- Single-Number Evaluation: During model development, teams often try many architectures and parameters. Having a single-number metric like F1 allows them to sort models and quickly decide which ideas are working best without struggling to compare two separate values (precision and recall).
- Addressing Class Imbalance: In a scenario where the positive class is rare (e.g., 1 in 1,000,000), a "dumb" model that always predicts "negative" will have near-perfect accuracy but zero recall and an undefined or zero F1-score, correctly identifying it as useless.
- Trust and Reliability: It captures a model's "trustworthiness" (precision) and "inclusivity" (recall) simultaneously, making it a better proxy for human intuition of a "good" model than accuracy.
- Interpretability and Limitations
- Difficulty of Interpretation: A primary disadvantage is that F1-scores are harder to explain and interpret to stakeholders than simple accuracy.
- Asymmetry: The F1-score is an asymmetric metric; its value changes depending on which class is declared the positive class. For example, if a model for cancer detection has an F1 of 0.17 for the "cancer" class, it might have an F1 of 0.95 for the "normal" class.
- Single Operating Point: The F1-score only captures performance at one specific decision threshold (usually the default 0.5). It does not provide the same detailed insight as a full Precision-Recall Curve, which shows tradeoffs across all possible thresholds.
- Multiclass Variations
To evaluate multiclass problems, binary F1-scores are computed for each class and then averaged using different strategies:
- Macro Averaging: Computes the unweighted average of per-class F1-scores, treating all classes as equally important regardless of their size.
- Weighted Averaging: Computes the average of per-class F1-scores weighted by support (the number of true instances in each class), making it more representative of the overall dataset distribution.
- Micro Averaging: Computes total TP, FP, and FN across all classes first, and then calculates a single F1-score. This is recommended if you care about each individual sample equally.
- The Generalized F-Measure (Fβ)
In many contexts, precision and recall are not equally important. The generalized Fβ score allows practitioners to weight them differently.
- Formula: Fβ=(1+β2)×(β2×Precision)+RecallPrecision×Recall.
- F2 Score (β=2): Weighs recall twice as high as precision, useful when missing a case is very costly (e.g., shoplifter detection or medical screening).
- F0.5 Score (β=0.5): Weighs precision twice as high as recall, useful when false alarms are dangerous (e.g., kid-safe video filters).