Log Loss (Cross-Entropy)
Log Loss, often used synonymously with Cross-Entropy, is the standard objective function for classification models that output probabilities, such as logistic regression and neural networks. It measures the performance of a model by comparing its predicted probability distribution against the actual ground truth labels.
1. The Information Theory Foundation
Cross-entropy originated in information theory as a measure of the distance between two probability distributions.
-
Entropy (H): Represents the intrinsic uncertainty or "average surprisal" of a distribution. It is the lower bound on the number of bits (or nats) needed to encode data.
-
Cross-Entropy (Hce): Measures the average number of bits required to identify an event from a distribution P if we use a coding scheme designed for a different distribution Q.
-
KL Divergence (DKL): The difference between these two (Hce−H) represents the "extra" information or bits wasted by using the incorrect distribution Q to model P.
-
Optimization Link: In machine learning, minimizing cross-entropy is mathematically equivalent to minimizing the KL Divergence between the empirical data distribution and the model's predicted distribution.
2. Mathematical Formulas
Log loss calculates a continuous-valued score for each instance rather than a discrete 0-1 error.
- Binary Cross-Entropy (Log Loss): For two classes (y∈{0,1}), the formula is:
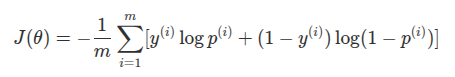
where p(i) is the model's predicted probability for class 1.
- Categorical Cross-Entropy: For multiclass problems (K classes) with one-hot encoded labels, it is defined as:
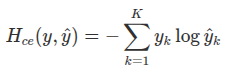
- Because only one class is "true" (yk=1), this simplifies to taking the negative log of the probability assigned to the correct class.
3. Interpretation and Behavior
The primary purpose of log loss is to punish confident incorrect predictions.
-
Penalty Logic: The term −log(p) grows toward infinity as the predicted probability p for the correct class approaches 0. Conversely, if the model predicts the correct class with 100% certainty, the loss is 0.
-
Confidence vs. Accuracy: A model might have high accuracy but a poor (high) log loss if it is frequently unsure about its correct predictions or highly confident in its mistakes.
-
Proper Scoring Rule: Log loss is a "proper scoring rule," meaning its minimum value is achieved if and only if the model's predicted probabilities exactly match the true underlying probabilities of the data.
4. Relationship to Maximum Likelihood Estimation (MLE)
In statistical terms, minimizing the Negative Log-Likelihood (NLL) of a model is exactly the same as minimizing its cross-entropy.
-
Probability Interpretation: Training a model via MLE involves choosing parameters that make the observed training data most "likely" according to the model.
-
Log-Transformation: Maximizing the likelihood is mathematically equivalent to maximizing the log of the likelihood because log is a monotonic function. Working with logs is preferred to avoid numerical underflow caused by multiplying many small probabilities together.
5. Training Advantages: Why not use MSE?
While Mean Squared Error (MSE) is standard for regression, cross-entropy is preferred for classification due to its gradient behavior.
-
Saturation and Vanishing Gradients: Activation functions like sigmoid and softmax saturate (become very flat) at extreme values, making their gradients nearly zero.
-
The "Log Trick": The log function in cross-entropy "undoes" the exponential in the sigmoid/softmax functions. This ensures that the gradient remains large and informative even when the model is very wrong, leading to faster convergence and better generalization than MSE.
6. Numerical Stability: The LogSumExp Trick
In practical implementations, computing log(softmax(a)) directly can lead to numerical overflow if the input values (logits) are large.
-
Stabilized Implementation: Most deep learning frameworks use the LogSumExp trick, which rearranges the math to compute the log-softmax in a way that keeps numbers in a manageable range.
-
Direct Logit Input: For this reason, it is often recommended to pass unnormalized "logits" directly into the loss function rather than pre-computing probabilities.